Mybatis
Mybatis
1.#{}和${}的区别是什么?
${}是 Properties 文件中的变量占位符,它可以用于标签属性值和 sql 内部,属于静态文本替换,比如${driver}会被静态替换为com.mysql.jdbc. Driver。#{}是 sql 的参数占位符,MyBatis 会将 sql 中的#{}替换为? 号,在 sql 执行前会使用 PreparedStatement 的参数设置方法,按序给 sql 的? 号占位符设置参数值,比如 ps.setInt(0, parameterValue),#{item.name}的取值方式为使用反射从参数对象中获取 item 对象的 name 属性值,相当于param.getItem().getName()。
2.Xml 映射文件中,除了常见的 select|insert|update|delete 标签之外,还有哪些标签?
还有很多其他的标签, <resultMap> 、 <parameterMap> 、 <sql> 、 <include> 、 <selectKey> ,加上动态 sql 的 9 个标签, trim|where|set|foreach|if|choose|when|otherwise|bind 等,其中 <sql> 为 sql 片段标签,通过 <include> 标签引入 sql 片段, <selectKey> 为不支持自增的主键生成策略标签。
3.通常一个 Xml 映射文件,都会写一个 Dao 接口与之对应,请问,这个 Dao 接口的工作原理是什么?Dao 接口里的方法,参数不同时,方法能重载吗?
Dao 接口,就是人们常说的 Mapper 接口,接口的全限名,就是映射文件中的 namespace 的值,接口的方法名,就是映射文件中 MappedStatement 的 id 值,接口方法内的参数,就是传递给 sql 的参数。 Mapper 接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为 key 值,可唯一定位一个 MappedStatement , 在 MyBatis 中,每一个 <select> 、 <insert> 、 <update> 、 <delete> 标签,都会被解析为一个 MappedStatement 对象。
Dao 接口里的方法可以重载,但是 Mybatis 的 XML 里面的 ID 不允许重复。Mybatis 的 Dao 接口可以有多个重载方法,但是多个接口对应的映射必须只有一个,否则启动会报错。
Dao 接口的工作原理是 JDK 动态代理,MyBatis 运行时会使用 JDK 动态代理为 Dao 接口生成代理 proxy 对象,代理对象 proxy 会拦截接口方法,转而执行 MappedStatement 所代表的 sql,然后将 sql 执行结果返回
4.MyBatis 是如何进行分页的?分页插件的原理是什么?
(1) MyBatis 使用 RowBounds 对象进行分页,它是针对 ResultSet 结果集执行的内存分页,而非物理分页;
(2) 可以在 sql 内直接书写带有物理分页的参数来完成物理分页功能;
(3) 也可以使用分页插件来完成物理分页。
分页插件的基本原理是使用 MyBatis 提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的 sql,然后重写 sql,根据 dialect 方言,添加对应的物理分页语句和物理分页参数。
举例: select _ from student ,拦截 sql 后重写为: select t._ from (select \* from student)t limit 0,10
5.说说Mybatis的缓存机制:
Mybatis整体: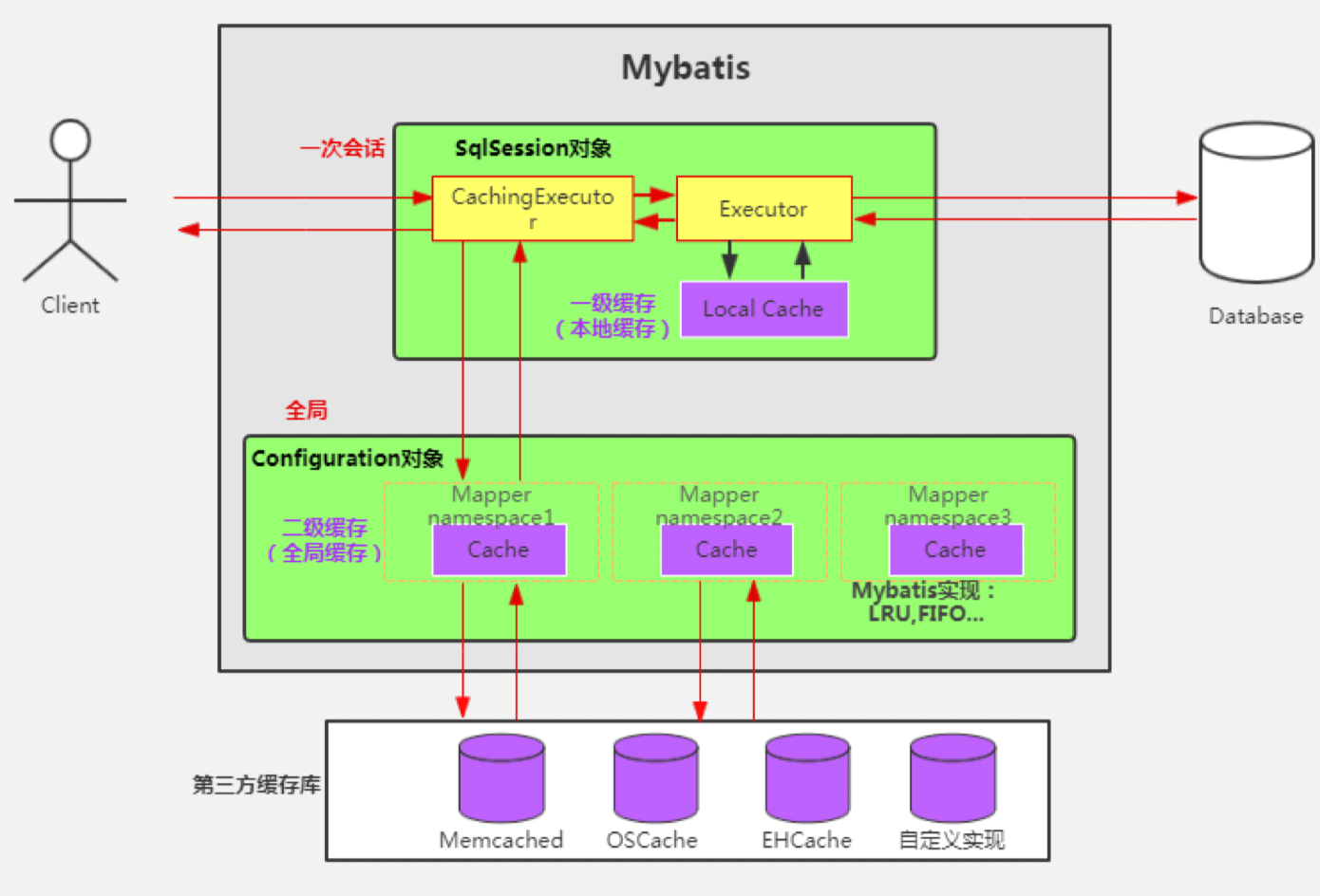
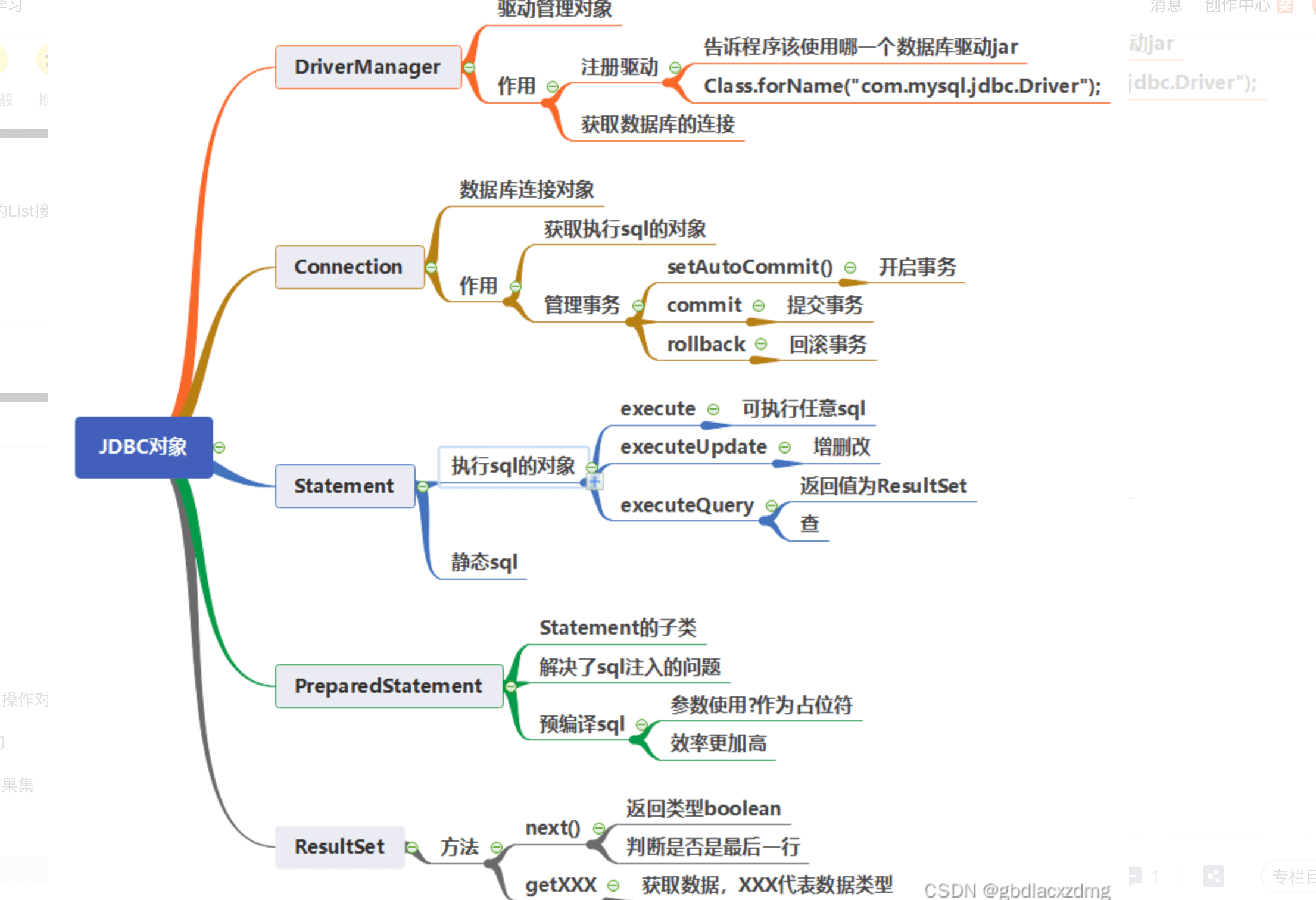
一级缓存localCache
在应用运行过程中,我们有可能在一次数据库会话中,执行多次查询条件完全相同的 SQL, MyBatis 提供了一级缓存的方案优化这部分场景,如果是相同的 SQL 语句,会优先命中一级缓存, 避免直接对数据库进行查询,提高性能。 每个 SqlSession 中持有了 Executor,每个 Executor 中有一个 LocalCache。当用户发起查询时, MyBatis 根据当前执行的语句生成 MappedStatement,在 Local Cache 进行查询,如果缓存命中 的话,直接返回结果给用户,如果缓存没有命中的话,查询数据库,结果写入 Local Cache,最后 返回结果给用户。具体实现类的类关系图如下图所示:
MyBatis 一级缓存的生命周期和 SqlSession 一致。
MyBatis 一级缓存内部设计简单,只是一个没有容量限定的 HashMap,在缓存的功能性上有 所欠缺。
MyBatis 的一级缓存最大范围是 SqlSession 内部,有多个 SqlSession 或者分布式的环境下, 数据库写操作会引起脏数据,建议设定缓存级别为 Statement。
二级缓存
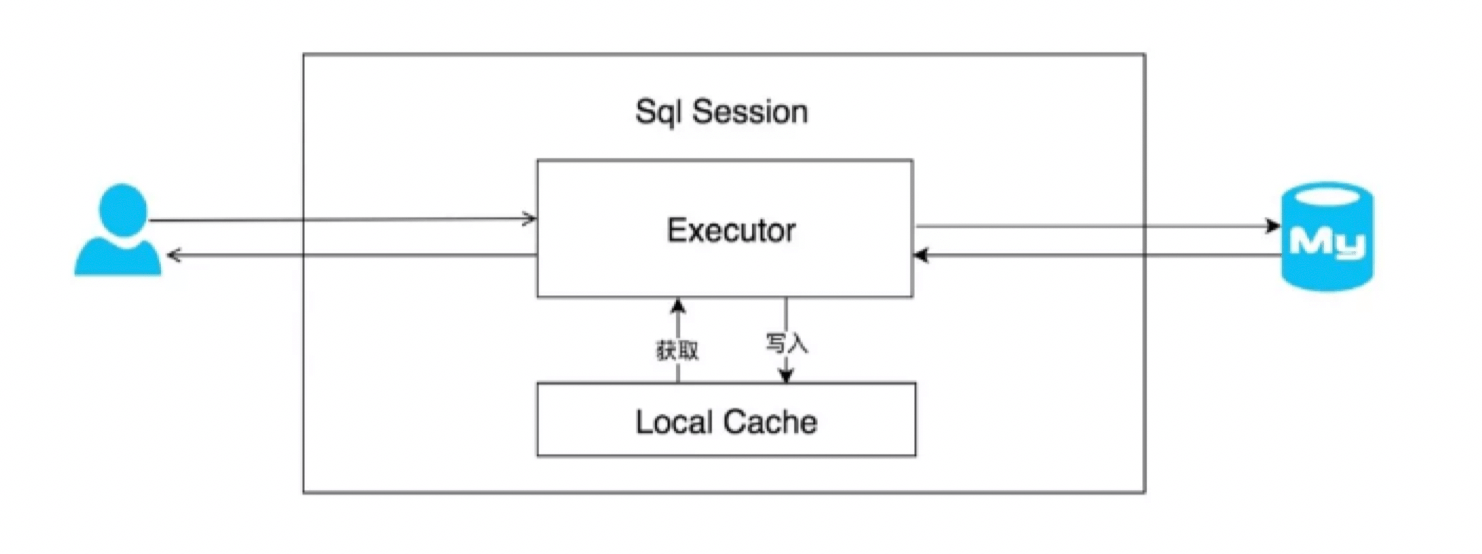
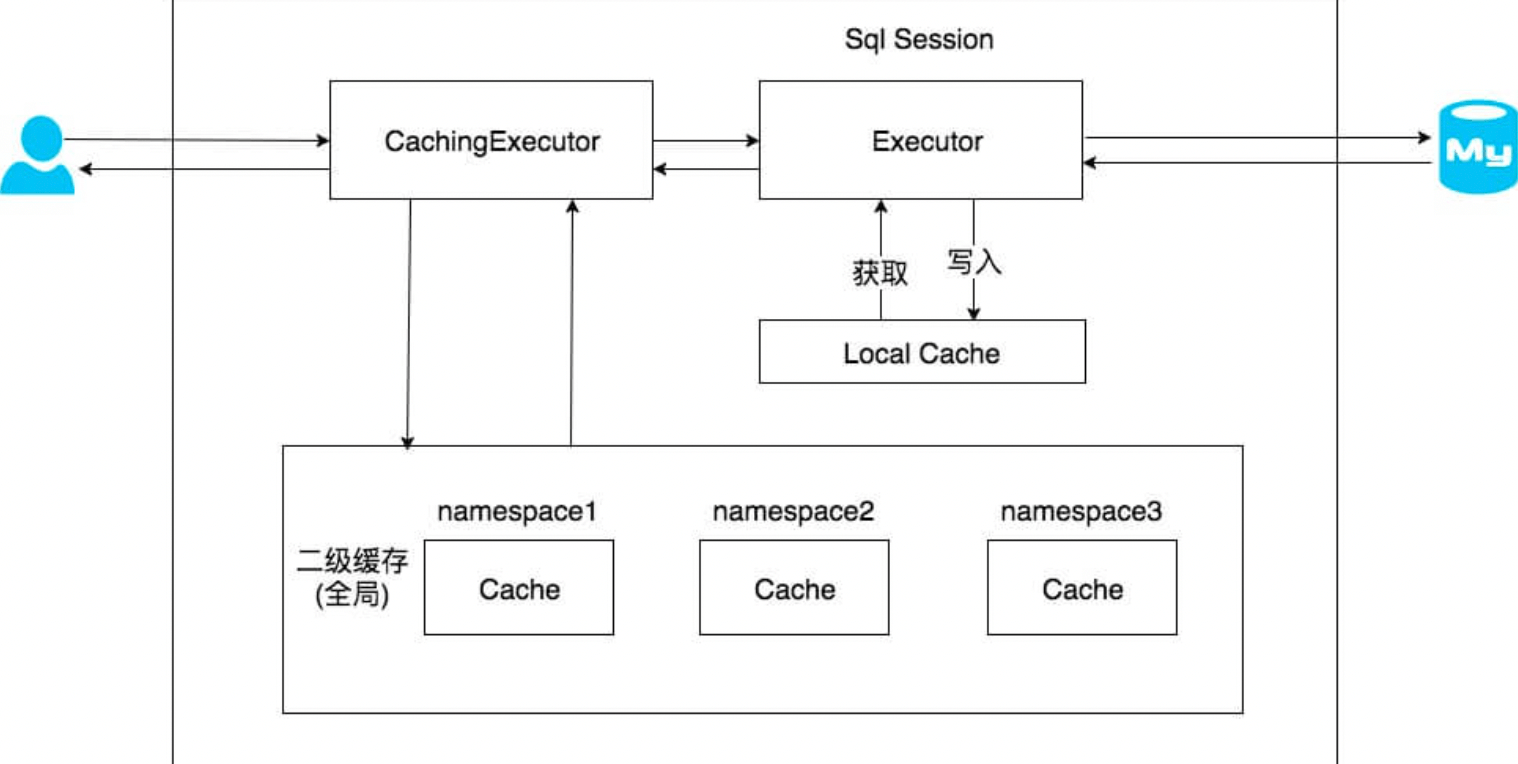
在上文中提到的一级缓存中,其最大的共享范围就是一个 SqlSession 内部,如果多个 SqlSession 之间需要共享缓存,则需要使用到二级缓存。开启二级缓存后,会使用 CachingExecutor 装饰 Executor,进入一级缓存的查询流程前,先在 CachingExecutor 进行二级缓存的查询,具体的工作 流程如下所示。
二级缓存开启后,同一个 namespace 下的所有操作语句,都影响着同一个 Cache,即二级缓存被 多个 SqlSession 共享,是一个全局的变量。
当开启缓存后,数据的查询执行的流程为:
二级缓存 -> 一级缓存 -> 数据库
MyBatis 的二级缓存相对于一级缓存来说,实现了 SqlSession 之间缓存数据的共享,同时粒度 更加细,能够到 namespace 级别,通过 Cache 接口实现类不同的组合,对 Cache 的可控性 也更强。
MyBatis 在多表查询时,极大可能会出现脏数据,有设计上的缺陷,安全使用二级缓存的条件 比较苛刻。
在分布式环境下,由于默认的 MyBatis Cache 实现都是基于本地的,分布式环境下必然会出现 读取到脏数据,需要使用集中式缓存将 MyBatis 的 Cache 接口实现,有一定的开发成本,直 接使用 Redis、Memcached 等分布式缓存可能成本更低,安全性也更高。
6.什么是 Mybatis?
1、Mybatis 是一个半 ORM(对象关系映射)框架, 它内部封装了 JDBC, 开发时 只需要关注 SQL 语句本身, 不需要花费精力去处理加载驱动、创建连接、创建 statement 等繁杂的过程。 程序员直接编写原生态 sql, 可以严格控制 sql 执行性 能, 灵活度高。
2、MyBatis 可以使用 XML 或注解来配置和映射原生信息, 将 POJO 映射成数 据库中的记录, 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。
3、通过 xml 文件或注解的方式将要执行的各种 statement 配置起来, 并通过 java 对象和 statement 中 sql 的动态参数进行映射生成最终执行的 sql 语句, 最 后由 mybatis 框架执行 sql 并将结果映射为 java 对象并返回。 (从执行 sql 到返 回 result 的过程)。
7.MyBatis 编程步骤
- 创建 SqlSessionFactory 对象。
- 通过 SqlSessionFactory 获取 SqlSession 对象。
- 通过 SqlSession 获得 Mapper 代理对象。
- 通过 Mapper 代理对象,执行数据库操作。
- 执行成功,则使用 SqlSession 提交事务。
- 执行失败,则使用 SqlSession 回滚事务。
- 最终,关闭会话。
8.Mybatis 动态 SQL 是做什么的?都有哪些动态 SQL ?能简述一下动态 SQL 的执行原理吗?
- Mybatis 动态 SQL ,可以让我们在 XML 映射文件内,以 XML 标签的形式编写动态 SQL ,完成逻辑判断和动态拼接 SQL 的功能。
- Mybatis 提供了 9 种动态 SQL 标签:
<if />、<choose />、<when />、<otherwise />、<trim />、<where />、<set />、<foreach />、<bind />。 - 其执行原理为,使用 OGNL 的表达式,从 SQL 参数对象中计算表达式的值,根据表达式的值动态拼接 SQL ,以此来完成动态 SQL 的功能。
9.通常一个 XML 映射文件,都会写一个 Mapper 接口与之对应。请问,这个 Mapper 接口的工作原理是什么?Mapper 接口里的方法,参数不同时,方法能重载吗?
Mapper 接口,对应的关系如下:
- 接口的全限名,就是映射文件中的
"namespace"的值。 - 接口的方法名,就是映射文件中 MappedStatement 的
"id"值。 - 接口方法内的参数,就是传递给 SQL 的参数。
Mapper 接口是没有实现类的,当调用接口方法时,接口全限名 + 方法名拼接字符串作为 key 值,可唯一定位一个对应的 MappedStatement 。举例:com.mybatis3.mappers.StudentDao.findStudentById ,可以唯一找到 "namespace" 为 com.mybatis3.mappers.StudentDao 下面 "id" 为 findStudentById 的 MappedStatement 。
总结来说,在 Mybatis 中,每一个 <select />、<insert />、<update />、<delete /> 标签,都会被解析为一个 MappedStatement 对象。
另外,Mapper 接口的实现类,通过 MyBatis 使用 JDK Proxy 自动生成其代理对象 Proxy ,而代理对象 Proxy 会拦截接口方法,从而“调用”对应的 MappedStatement 方法,最终执行 SQL ,返回执行结果。整体流程如下图:
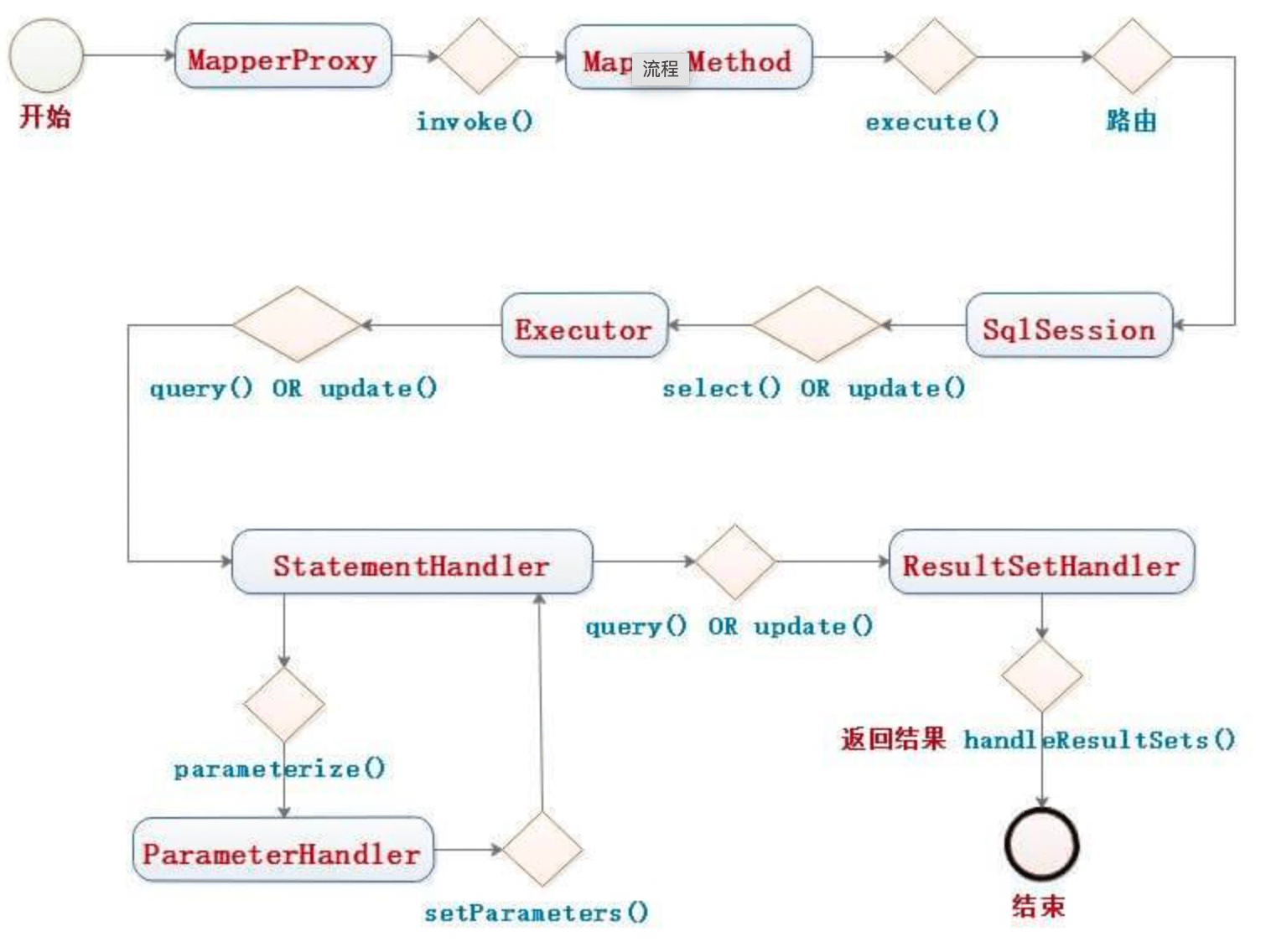
10.Mybatis 都有哪些 Executor 执行器?它们之间的区别是什么?
Mybatis 有四种 Executor 执行器,分别是 SimpleExecutor、ReuseExecutor、BatchExecutor、CachingExecutor 。
- SimpleExecutor :每执行一次 update 或 select 操作,就创建一个 Statement 对象,用完立刻关闭 Statement 对象。
- ReuseExecutor :执行 update 或 select 操作,以 SQL 作为key 查找缓存的 Statement 对象,存在就使用,不存在就创建;用完后,不关闭 Statement 对象,而是放置于缓存
Map<String, Statement>内,供下一次使用。简言之,就是重复使用 Statement 对象。 - BatchExecutor :执行 update 操作(没有 select 操作,因为 JDBC 批处理不支持 select 操作),将所有 SQL 都添加到批处理中(通过 addBatch 方法),等待统一执行(使用 executeBatch 方法)。它缓存了多个 Statement 对象,每个 Statement 对象都是调用 addBatch 方法完毕后,等待一次执行 executeBatch 批处理。实际上,整个过程与 JDBC 批处理是相同。
- CachingExecutor :在上述的三个执行器之上,增加二级缓存的功能。
通过设置 <setting name="defaultExecutorType" value=""> 的 "value" 属性,可传入 SIMPLE、REUSE、BATCH 三个值,分别使用 SimpleExecutor、ReuseExecutor、BatchExecutor 执行器。
通过设置 <setting name="cacheEnabled" value="" 的 "value" 属性为 true 时,创建 CachingExecutor 执行器。
11.MyBatis 如何执行批量插入?
首先,在 Mapper XML 编写一个简单的 Insert 语句。代码如下:
<insert id="insertUser" parameterType="String">
INSERT INTO users(name)
VALUES (#{value})
</insert>
然后,然后在对应的 Mapper 接口中,编写映射的方法。代码如下:
public interface UserMapper {
void insertUser(@Param("name") String name);
}
最后,调用该 Mapper 接口方法。代码如下:
private static SqlSessionFactory sqlSessionFactory;
@Test
public void testBatch() {
// 创建要插入的用户的名字的数组
List<String> names = new ArrayList<>();
names.add("占小狼");
names.add("朱小厮");
names.add("徐妈");
names.add("飞哥");
// 获得执行器类型为 Batch 的 SqlSession 对象,并且 autoCommit = false ,禁止事务自动提交
try (SqlSession session = sqlSessionFactory.openSession(ExecutorType.BATCH, false)) {
// 获得 Mapper 对象
UserMapper mapper = session.getMapper(UserMapper.class);
// 循环插入
for (String name : names) {
mapper.insertUser(name);
}
// 提交批量操作
session.commit();
}
}
代码比较简单,胖友仔细看看。当然,还有另一种方式,代码如下:
INSERT INTO [表名]([列名],[列名])
VALUES
([列值],[列值])),
([列值],[列值])),
([列值],[列值]));
- 对于这种方式,需要保证单条 SQL 不超过语句的最大限制
max_allowed_packet大小,默认为 1 M
12.Mybatis 映射文件中,如果 A 标签通过 include 引用了B标签的内容,请问,B 标签能否定义在 A 标签的后面,还是说必须定义在A标签的前面?
虽然 Mybatis 解析 XML 映射文件是按照顺序解析的。但是,被引用的 B 标签依然可以定义在任何地方,Mybatis 都可以正确识别。也就是说,无需按照顺序,进行定义。
原理是,Mybatis 解析 A 标签,发现 A 标签引用了 B 标签,但是 B 标签尚未解析到,尚不存在,此时,Mybatis 会将 A 标签标记为未解析状态。然后,继续解析余下的标签,包含 B 标签,待所有标签解析完毕,Mybatis 会重新解析那些被标记为未解析的标签,此时再解析A标签时,B 标签已经存在,A 标签也就可以正常解析完成了。
13.mybatis缓存模块
MyBatis 中提供了一级缓存和二级缓存,而这两级缓存都是依赖于基础支持层中的缓 存模块实现的。这里需要读者注意的是,MyBatis 中自带的这两级缓存与 MyBatis 以及整个应用是运行在同一个 JVM 中的,共享同一块堆内存。如果这两级缓存中的数据量较大, 则可能影响系统中其他功能的运行,所以当需要缓存大量数据时,优先考虑使用 Redis、Memcache 等缓存产品。
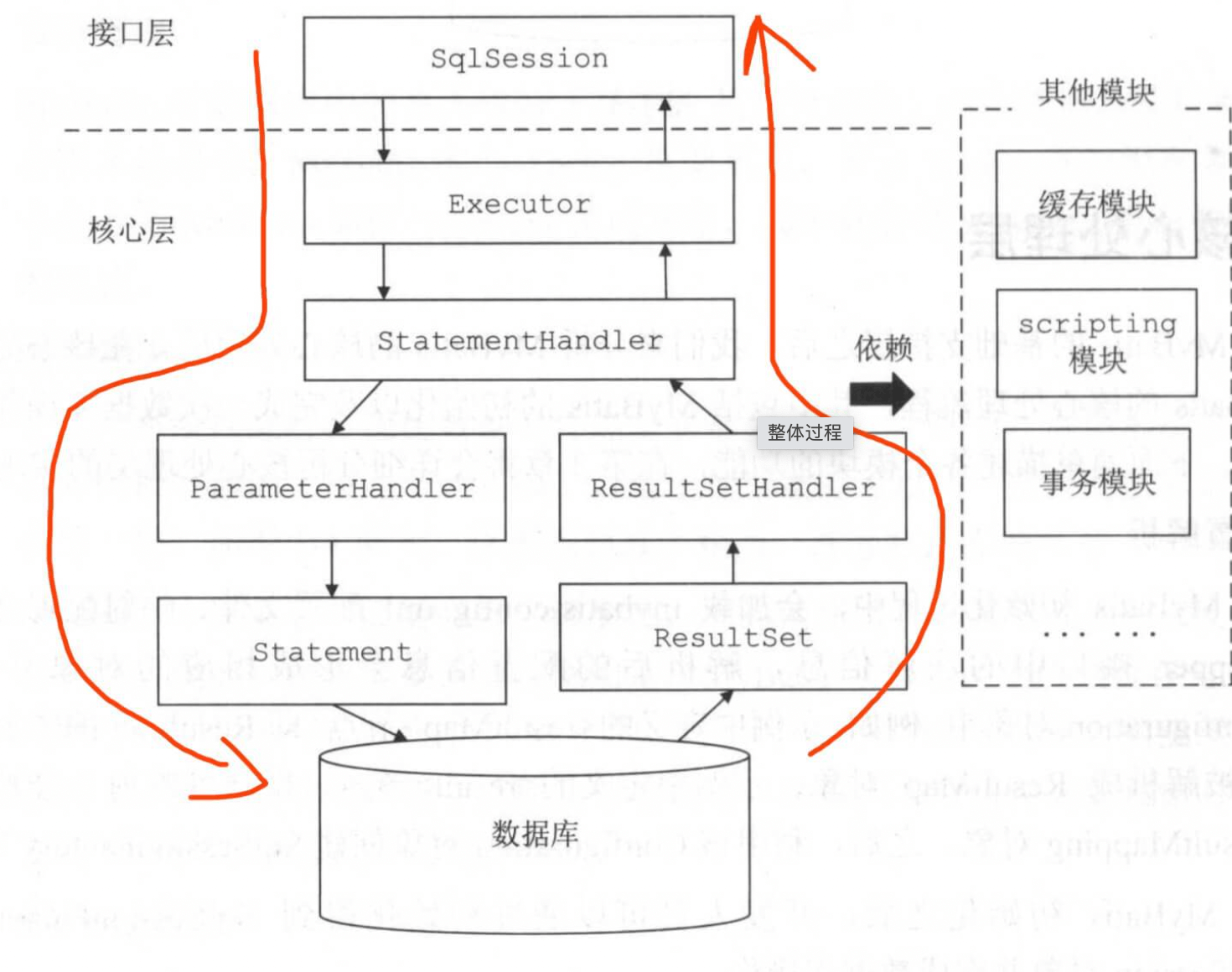
14.mybatis sql执行整体过程
SQL 语句的执行涉及多个组件 ,其中比较重要的是 Executor、StatementHandler、ParameterHandler 和 ResultSetHandler 。
- Executor 主要负责维护一级缓存和二级缓存,并提供事务管理的相关操作,它会将数据库相关操作委托给 StatementHandler完成。
- StatementHandler 首先通过 ParameterHandler 完成 SQL 语句的实参绑定,然后通过
java.sql.Statement对象执行 SQL 语句并得到结果集,最后通过 ResultSetHandler 完成结果集的映射,得到结果对象并返回。
整体过程如下图:
15.mybatis连接池添加连接与获取连接
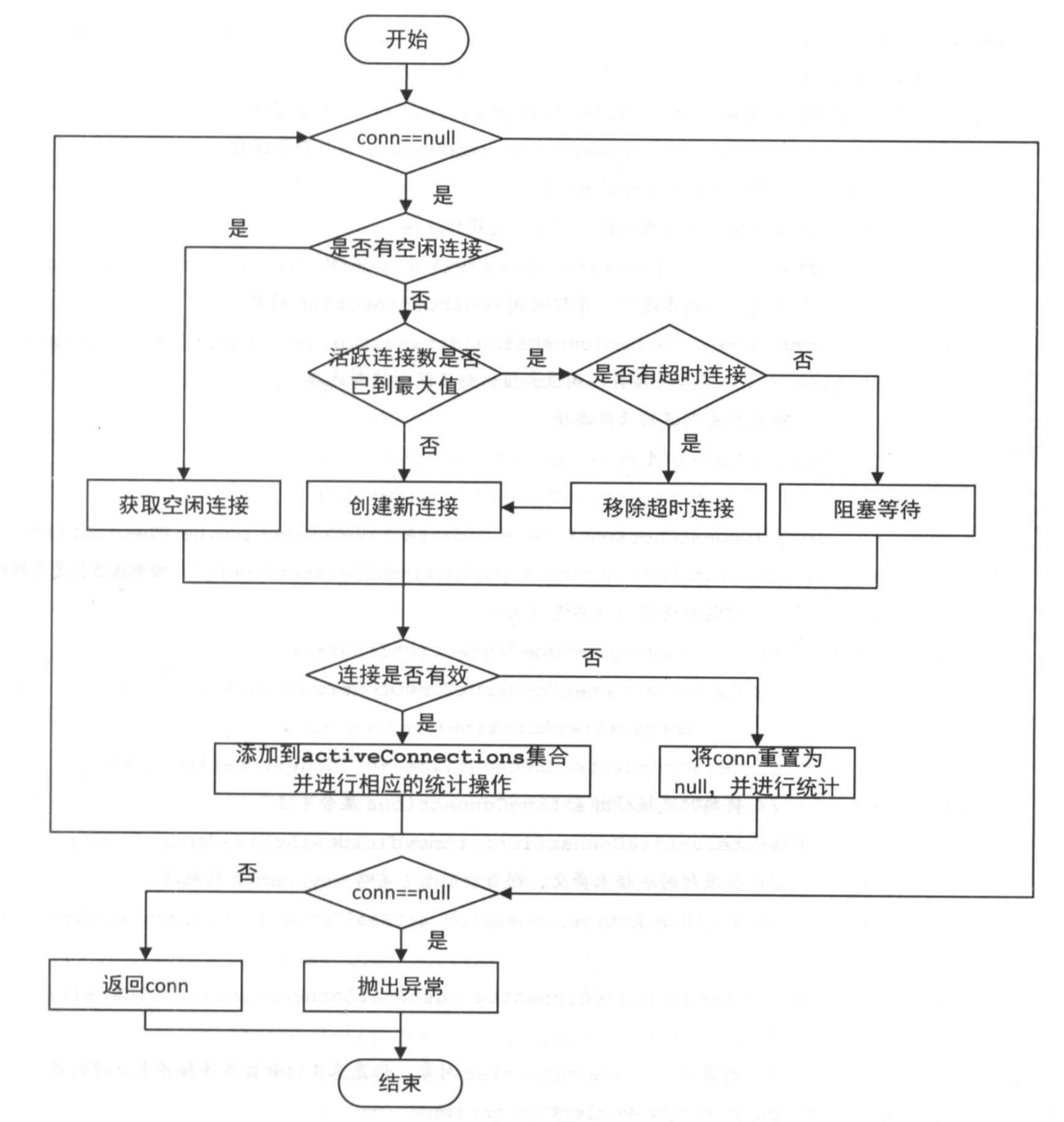

16.什么是mybatis一级缓存、二级缓存
每当我们使用 MyBatis 开启一次和数据库的会话,MyBatis 会创建出一个 SqlSession 对象表示一次数据库会话,而每个 SqlSession 都会创建一个 Executor 对象。
在对数据库的一次会话中,我们有可能会反复地执行完全相同的查询语句,如果不采取一些措施的话,每一次查询都会查询一次数据库,而我们在极短的时间内做了完全相同的查询,那么它们的结果极有可能完全相同,由于查询一次数据库的代价很大,这有可能造成很大的资源浪费。
为了解决这一问题,减少资源的浪费,MyBatis 会在表示会话的SqlSession 对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来,当下次查询的时候,如果判断先前有个完全一样的查询,会直接从缓存中直接将结果取出,返回给用户,不需要再进行一次数据库查询了。 注意,这个“简单的缓存”就是一级缓存,且默认开启,无法关闭。
如下图所示,MyBatis 会在一次会话的表示 —— 一个 SqlSession 对象中创建一个本地缓存( localCache ),对于每一次查询,都会尝试根据查询的条件去本地缓存中查找是否在缓存中,如果在缓存中,就直接从缓存中取出,然后返回给用户;否则,从数据库读取数据,将查询结果存入缓存并返回给用户。
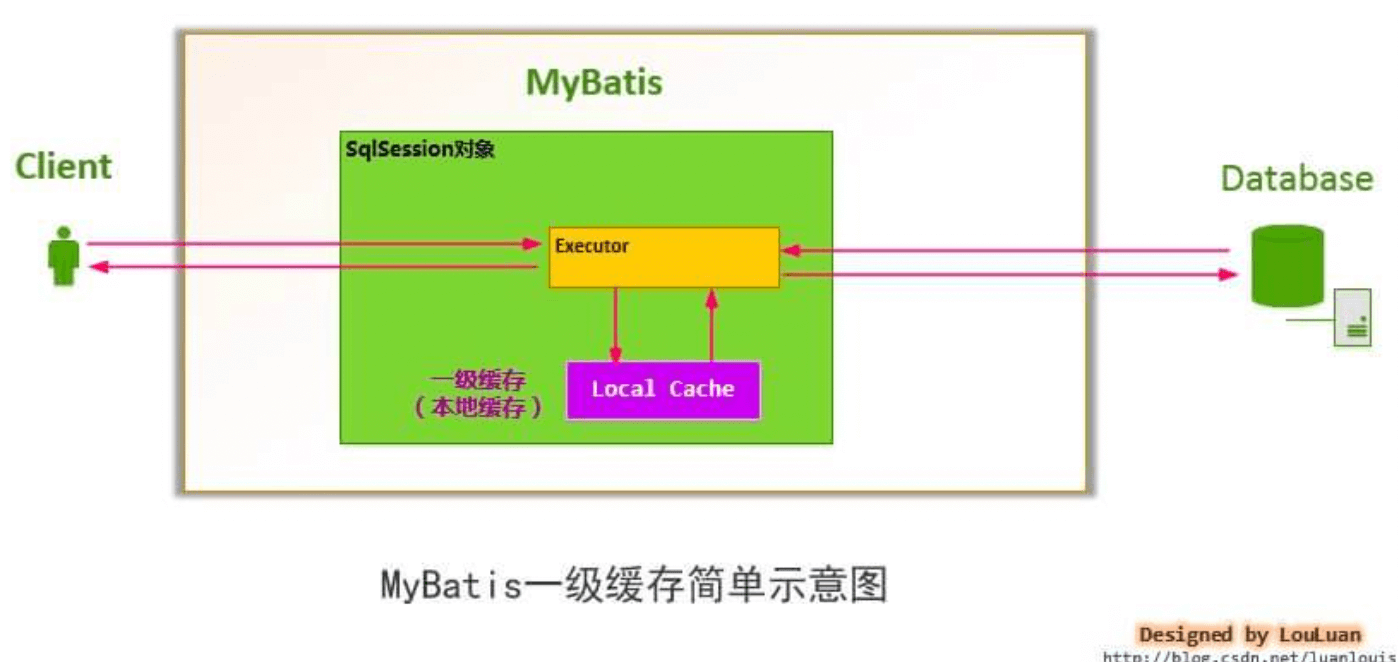
在上文中提到的一级缓存中,其最大的共享范围就是一个 SqlSession 内部,如果多个 SqlSession 之间需要共享缓存,则需要使用到二级缓存。开启二级缓存后,会使用 CachingExecutor 装饰 Executor ,进入一级缓存的查询流程前,先在 CachingExecutor 进行二级缓存的查询,具体的工作流程如下所示。
17.BatchExecutor
BatchExecutor ,继承 BaseExecutor 抽象类,批量执行的 Executor 实现类。
执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理的;BatchExecutor相当于维护了多个桶,每个桶里都装了很多属于自己的SQL,就像苹果蓝里装了很多苹果,番茄蓝里装了很多番茄,最后,再统一倒进仓库。(可以是Statement或PrepareStatement对象)
18.jdbc编程步骤
一、注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");//类加载注册
二、获取连接
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/数据库名?useUnicode=true&characterEncoding=utf8&useSSL=false","用户名","密码")
三、获取数据库操作对象
stat = conn.createStatement();
四、设置传入参数
stat.setString(1,"zhangsan");
五、执行sql语句
String sql = "select * from userinfo where user_id=?";
rs = stat.executeQuery(sql);
六、处理查询结果集
while (rs.next()){
String name = rs.getString("first_name");
String money = rs.getString("salary");
String id = rs.getString("job_id");
System.out.println(name + "," + money + "," + id);
}
七、释放资源
if(rs != null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(stat != null){
try {
stat.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(conn != null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}